Pretraining a GAN using an autoencoder
Introduction¶
In my previous post I demonstrated the concept of an autoencoder, a machine learning system that learns to output its input and in the process works toward some auxiliary objective.
In this project, I'm going to introduce the concept of a GAN, and use an autoencoder to give a boost to the training process.
What is a GAN?¶
GAN stands for Generative Adversarial Network. Generative means the system will create content (in this case, images) rather than, say, classifying it. Adversarial means the system will train its components competitively. Network because the system will be implemented as a neural network.
The diagram below depicts GAN structure. I will describe the structure in terms of a GAN that generates images.
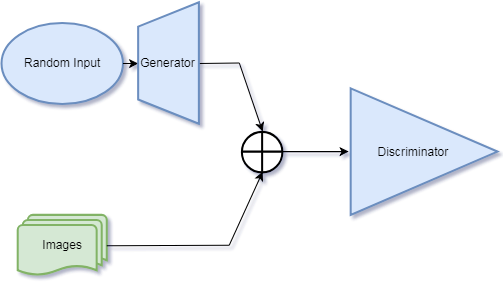
A GAN consists of two main components, the generator and the discriminator. The generator generates an image seeded by a random input. The discriminator is a classifier that takes as input either an image from the generator or an image from a preselected dataset containing images typical of what we wish to train the generator to produce.
The key is that the generator and discriminator are trained toward cross-purposes. The discriminator is trained to identify which images are "real", i.e. originating from the dataset or "fake", originating from the generator. The generator is trained to fool the discriminator.
In principle, as the discriminator gets better at distinguishing real from generated images, the generator must produce images that more convincingly blend into the dataset, which is our ultimate goal. In practice, it's hard to set up a GAN to reliably train, and this is still an active area of research.
For this project my original goal was to work through a notebook featuring a GAN that appeared in the 2018 version of fast.ai's online course. When I ran into trouble getting the network to train, I found a solution involving an autoencoder.
Setup¶
%matplotlib inline
%reload_ext autoreload
%autoreload 2
This code uses an old version (0.7) of the fast.ai library, which I've symlinked under oldfastai.
from oldfastai.conv_learner import *
from oldfastai.dataset import *
import gzip
torch.cuda.set_device(0)
We will use a portion of the LSUN scene classification dataset, specifically a 20% sample of the bedroom scenes which can be downloaded here.
PATH = Path('data/lsun/')
IMG_PATH = PATH/'bedroom'
CSV_PATH = PATH/'files.csv'
TMP_PATH = PATH/'tmp'
TMP_PATH.mkdir(exist_ok=True)
The dataset has a complicated directory structure. Here we just want to use all the images.
files = PATH.glob('bedroom/**/*.jpg')
with CSV_PATH.open('w') as fo:
for f in files: fo.write(f'{f.relative_to(IMG_PATH)},0\n')
Define Encoder / Decoder¶
The code for the discriminator, generator, their components, some utility functions, and the training loop is courtesy of Jeremy Howard and is pulled directly from the aforementioned notebook.
class ConvBlock(nn.Module):
def __init__(self, ni, no, ks, stride, bn=True, pad=None):
super().__init__()
if pad is None: pad = ks//2//stride
self.conv = nn.Conv2d(ni, no, ks, stride, padding=pad, bias=False)
self.bn = nn.BatchNorm2d(no) if bn else None
self.relu = nn.LeakyReLU(0.2, inplace=True)
def forward(self, x):
x = self.relu(self.conv(x))
return self.bn(x) if self.bn else x
class DCGAN_D(nn.Module):
def __init__(self, isize, nc, ndf, n_extra_layers=0):
super().__init__()
assert isize % 16 == 0, "isize has to be a multiple of 16"
self.initial = ConvBlock(nc, ndf, 4, 2, bn=False)
csize,cndf = isize/2,ndf
self.extra = nn.Sequential(*[ConvBlock(cndf, cndf, 3, 1)
for t in range(n_extra_layers)])
pyr_layers = []
while csize > 4:
pyr_layers.append(ConvBlock(cndf, cndf*2, 4, 2))
cndf *= 2; csize /= 2
self.pyramid = nn.Sequential(*pyr_layers)
self.final = nn.Conv2d(cndf, 1, 4, padding=0, bias=False)
def forward(self, input):
x = self.initial(input)
x = self.extra(x)
x = self.pyramid(x)
return self.final(x).mean(0).view(1)
Jeremy mentions artifacts being an issue with the ConvTranspose operation, but uses it here anyway (presumably it worked well enough for this purpose). ConvTranspose has worked fine for me in building an autoencoder for MNIST but it may be the culprit of noticeable artifacts that can be seen later. Perhaps something that can be improved.
class DeconvBlock(nn.Module):
def __init__(self, ni, no, ks, stride, pad, bn=True):
super().__init__()
self.conv = nn.ConvTranspose2d(ni, no, ks, stride, padding=pad, bias=False)
self.bn = nn.BatchNorm2d(no)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.relu(self.conv(x))
return self.bn(x) if self.bn else x
class DCGAN_G(nn.Module):
def __init__(self, isize, nz, nc, ngf, n_extra_layers=0):
super().__init__()
assert isize % 16 == 0, "isize has to be a multiple of 16"
cngf, tisize = ngf//2, 4
while tisize!=isize: cngf*=2; tisize*=2
layers = [DeconvBlock(nz, cngf, 4, 1, 0)]
csize, cndf = 4, cngf
while csize < isize//2:
layers.append(DeconvBlock(cngf, cngf//2, 4, 2, 1))
cngf //= 2; csize *= 2
layers += [DeconvBlock(cngf, cngf, 3, 1, 1) for t in range(n_extra_layers)]
layers.append(nn.ConvTranspose2d(cngf, nc, 4, 2, 1, bias=False))
self.features = nn.Sequential(*layers)
def forward(self, input): return F.tanh(self.features(input))
Batch size, working image size, and dimension of our latent variables.
bs,sz,nz = 64,64,100
Create our modeldata...
tfms = tfms_from_stats(inception_stats, sz)
md = ImageClassifierData.from_csv(PATH, 'bedroom', CSV_PATH, tfms=tfms, bs=128,
skip_header=False, continuous=True)
md = md.resize(128)
x,_ = next(iter(md.val_dl))
We're going to be training our GAN to create images of bedrooms like this:
plt.imshow(md.trn_ds.denorm(x)[0]);

Initial instantiation of our generator and discriminator.
netG = DCGAN_G(sz, nz, 3, 64, 1).cuda()
netD = DCGAN_D(sz, 3, 64, 1).cuda()
A function to pick random vectors of dimension 100 from a standard normal distribution.
def create_noise(b): return V(torch.zeros(b, nz, 1, 1).normal_(0, 1))
Initial results of our generator. We don't expect much from a randomly initialized generator.
nn.functional.tanh = torch.tanh
preds = netG(create_noise(4))
pred_ims = md.trn_ds.denorm(preds)
fig, axes = plt.subplots(2, 2, figsize=(6, 6))
for i,ax in enumerate(axes.flat): ax.imshow(pred_ims[i])

def gallery(x, nc=3):
n,h,w,c = x.shape
nr = n//nc
assert n == nr*nc
return (x.reshape(nr, nc, h, w, c)
.swapaxes(1,2)
.reshape(h*nr, w*nc, c))
Training a GAN is different from a classifier. Jeremy implements a GAN training cycle manually.
def train(niter, first=True):
gen_iterations = 0
for epoch in trange(niter):
netD.train(); netG.train()
data_iter = iter(md.trn_dl)
i,n = 0,len(md.trn_dl)
with tqdm(total=n) as pbar:
while i < n:
set_trainable(netD, True)
set_trainable(netG, False)
d_iters = 100 if (first and (gen_iterations < 25) or (gen_iterations % 500 == 0)) else 5
j = 0
while (j < d_iters) and (i < n):
j += 1; i += 1
for p in netD.parameters(): p.data.clamp_(-0.01, 0.01)
real = V(next(data_iter)[0])
real_loss = netD(real)
fake = netG(create_noise(real.size(0)))
fake_loss = netD(V(fake.data))
netD.zero_grad()
lossD = real_loss-fake_loss
lossD.backward()
optimizerD.step()
pbar.update()
set_trainable(netD, False)
set_trainable(netG, True)
netG.zero_grad()
lossG = netD(netG(create_noise(bs))).mean(0).view(1)
lossG.backward()
optimizerG.step()
gen_iterations += 1
print(f'Loss_D {to_np(lossD)}; Loss_G {to_np(lossG)}; '
f'D_real {to_np(real_loss)}; Loss_D_fake {to_np(fake_loss)}')
len(md.trn_dl)
Initial attempts to train¶
torch.backends.cudnn.benchmark=True
optimizerD = optim.RMSprop(netD.parameters(), lr = 1e-4)
optimizerG = optim.RMSprop(netG.parameters(), lr = 1e-4)
train(1, True)
set_trainable(netD, True)
set_trainable(netG, True)
optimizerD = optim.RMSprop(netD.parameters(), lr = 1e-5)
optimizerG = optim.RMSprop(netG.parameters(), lr = 1e-5)
train(1, False)
Here are the results of the generator producing 4 images from 4 random vectors. Not much progress, it seems.
preds = netG(create_noise(4))
pred_ims = md.trn_ds.denorm(preds)
fig, axes = plt.subplots(2, 2, figsize=(6, 6))
for i,ax in enumerate(axes.flat): ax.imshow(pred_ims[i])

Let's try more training.
train(5, False)
Here again is a sample of the types of images the generator is producing.
preds = netG(create_noise(4))
pred_ims = md.trn_ds.denorm(preds)
fig, axes = plt.subplots(2, 2, figsize=(6, 6))
for i,ax in enumerate(axes.flat): ax.imshow(pred_ims[i])

Let's create a static set of one batch random vectors and track what the generator produces from those particular vectors.
fixed_noise = create_noise(bs)
netD.eval(); netG.eval();
fake = netG(fixed_noise).data.cpu()
faked = np.clip(md.trn_ds.denorm(fake),0,1)
plt.figure(figsize=(9,9))
plt.imshow(gallery(faked, 8));

It's hard to tell that's an $8\times 8$ array of images.
Autoencoder¶
Well that didn't work the way it was supposed to. A possible explanation for the discrepency between Jeremy's results and mine are that Jeremy used the full complement of the bedroom scenes in the LSUN dataset rather than the 20% sample I used. Another possibility is that Jeremy trained his GAN more than the few cycles he displayed in his notebook. It was at this point I decided to try an idea I had for pretraining.
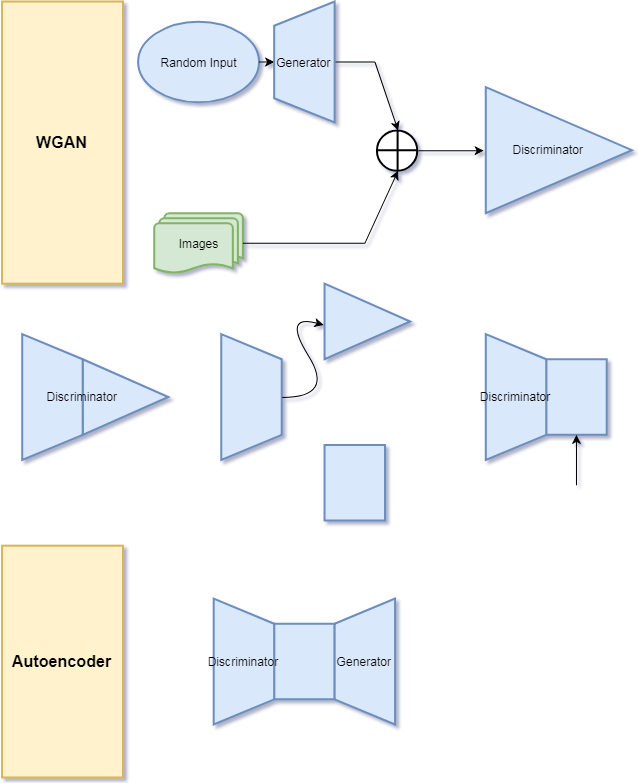
In a WGAN, the discriminator encodes the high dimensional image space to a lower dimensional latent-variable space and classifies it (real or fake) while the generator figures out how to turn a low(ish) dimensional latent random variable space and decode it into the high dimensional image space. This sounds like, respectively, the encoder and decoder of an autoencoder! A small problem is that the discriminator outputs a single number in the space $[-1,1]$ while the generator takes a vector from $\mathbb{R}^n$, but we can fix that by stripping off enough layers of the discriminator to get to higher dimensional space, and adding a translation layer that outputs in $\mathbb{R}^n$.
Why do this? Well firstly autoencoders are not that hard to train. Secondly I suspected that if the generator had some training in taking an encoding and generating bedroom images (specific images in fact) that would be helpful in producing bedroom-like images in general. Meanwhile the decoder would get some practice in extracting useful information from bedroom images.
The first thing we'll do is recreate the GAN. We're setting up an experiment to see whether pretraining a GAN as an autoencoder in this case is better than purely training as a GAN. With that in mind, we need to compare them directly, so it's not fair for the autoencoder method to benefit from the GAN training that's already occurred.
netG = DCGAN_G(sz, nz, 3, 64, 1).cuda()
netD = DCGAN_D(sz, 3, 64, 1).cuda()
Define autoencoder model¶
The summary provided by PyTorch / fast.ai isn't always helpful in determining the inputs and outputs of certain layers of the model(s), so I typically create a Torch tensor for testing.
x = T(md.val_ds[0][0].reshape((1,3,64,64)))
nn.Sequential(*children(netD)[:-1])(x).size()
It looks like if we strip off the last layer of the discriminator, we get an output that is $\mbox{bs}\times 512\times 4\times 4$, or a batch of 512 features each of which is a $4\times 4$ array. This is certainly high enough dimension for our purposes.
We need to add a translation layer, so we'll do a convolutional layer with a $4\times 4$ kernel, no padding, and an output of 100 features. This is similar to what the layer we removed from the discriminator did.
dec = nn.Sequential(*children(netD)[:-1]+[nn.Conv2d(512,100,4,bias=False)]).cuda()
dec(x).size()
We check, and voila! The shape matches the output of create_noise, which goes straight into netG.
create_noise(1).size()
Now we assemble the autoencoder.
autoenc = (nn.Sequential(dec,netG)).cuda()
Let's just make sure everything is lined up internally.
autoenc(x).size()
Create ModelData¶
An autoencoder is just a special case of a deep regression network, so we can leverage the standard fast.ai library.
Here's what the csv file we created earlier looks like. The column I've labelled "N/A" doesn't do anything. I assume it's there because the default behavior of fast.ai when creating modeldata from a csv is to look for filename/label pairs. For the GAN we're not interested in labels, and for the autoencoder the input and label are the same.
fn_df = pd.read_csv(CSV_PATH,header=None)
fn_df.columns = ["fn","N/A"]
fn_df.head()
Presumably we could use the csv file or the dataframe to make a dataset of data/label pairs for the autoencoder, but I found the following piece of code in a different notebook for the fast.ai course, which uses an array of Path objects.
class MatchedFilesDataset(FilesDataset):
def __init__(self, fnames, y, transform, path):
self.y=y
assert(len(fnames)==len(y))
super().__init__(fnames, transform, path)
def get_y(self, i): return open_image(os.path.join(self.path, self.y[i]))
def get_c(self): return 0
That's easy enough to create.
%time fns = np.array(['bedroom'/Path(row["fn"]) for i,row in fn_df.iterrows()])
fns[:5]
I pulled out and modified the following code from the same notebook, which also suits our purpose. This creates a list of validation ids, and specifies the data transformations to due for augmentation.
val_idxs = list(range(len(fns)//5))
((val_x,trn_x),(val_y,trn_y)) = split_by_idx(val_idxs, fns, fns)
aug_tfms = [RandomRotate(4, tfm_y=TfmType.PIXEL),
RandomFlip(tfm_y=TfmType.PIXEL),
RandomLighting(0.05, 0.05, tfm_y=TfmType.PIXEL)]
Now we create datasets and get our ModelData object.
ae_tfms = tfms_from_stats(inception_stats, sz, tfm_y=TfmType.PIXEL, aug_tfms=aug_tfms)
ae_datasets = ImageData.get_ds(MatchedFilesDataset, (trn_x,trn_y), (val_x,val_y), ae_tfms, path=PATH)
ae_md = ImageData(PATH, ae_datasets, bs, num_workers=16, classes=None)
denorm = md.trn_ds.denorm
ae_md = ae_md.resize(128)
Check to make sure we're getting what we expect from the dataloader.
x,y = next(iter(ae_md.trn_dl))
x.shape,y.shape
Now since everything is set up according to the way fast.ai is designed, we can go ahead and grab a learner with all it's bells and whistles. I didn't give too much thought to the optimizer and loss function, I just used what's worked for me with autoencoders before. From what I understand, it's better practice to include the encoded feature vector as part of the cost, but I'm not going to do any of that.
learn = Learner.from_model_data(autoenc, ae_md, opt_fn = optim.Adam, crit = F.mse_loss)
Find learning rate¶
learn.lr_find(start_lr = 1e-4)
learn.sched.plot(n_skip=400)

From the above, I chose a learning rate of .001. Now let's train for a cycle using an adaptive learning rate and see how we do.
Autoencoder training¶
lr = 1e-3
learn.fit(lr, 1, use_clr_beta=(20,10,15), cycle_len = 1)
# learn.load(f'AE_ph1') # Load if autoencoder has already been trained.
A look at how the autoencoder is performing.
i=1
fig = plt.figure()
((ax1,ax2)) = fig.subplots(1,2)
ax1.imshow(denorm(x)[i])
ax2.imshow(denorm(learn.model(x))[i])

Not bad! We could train some more, but our purpose isn't really to make an autoencoder, it's to jumpstart a WGAN. Let's save and get back to business.
learn.save(f'AE_ph1')
One nice thing about how everything is set up, is that netG and the decoder layer of our autoencoder are the same instance...
netG is children(autoenc)[1]
...and similarly all the layers of the encoder-part of our autoencoder are the same instances as all but the last layer of our discriminator.
all((a is b for a,b in zip(children(autoenc)[0],children(netD)[:-1])))
That means we can use the netG and netD as they are, without having to reinstance or copy over parameters. Similarly if the need arises we can switch back and forth between training the autoencoder and WGAN relatively painlessly (with a caveat I'll mention later).
Just for fun let's see how our gallery looks after training netG with the autoencoder.
netD.eval(); netG.eval();
fake = netG(fixed_noise).data.cpu()
faked = np.clip(md.trn_ds.denorm(fake),0,1)
plt.figure(figsize=(9,9))
plt.imshow(gallery(faked, 8));

It certainly looks different, but it's still a far cry from looking like bedrooms. Here's 4 generated from new random noise.
preds = netG(create_noise(4))
pred_ims = md.trn_ds.denorm(preds)
fig, axes = plt.subplots(2, 2, figsize=(6, 6))
for i,ax in enumerate(axes.flat): ax.imshow(pred_ims[i])

WGAN training, attempt #2¶
optimizerD = optim.RMSprop(netD.parameters(), lr = 1e-4)
optimizerG = optim.RMSprop(netG.parameters(), lr = 1e-4)
train(1, True)
set_trainable(netD, True)
set_trainable(netG, True)
optimizerD = optim.RMSprop(netD.parameters(), lr = 1e-5)
optimizerG = optim.RMSprop(netG.parameters(), lr = 1e-5)
train(1, False)
Looking at our gallery again, suddenly things have improved!
netD.eval(); netG.eval();
fake = netG(fixed_noise).data.cpu()
faked = np.clip(md.trn_ds.denorm(fake),0,1)
plt.figure(figsize=(9,9))
plt.imshow(gallery(faked, 8));

Looking more closely, we can see that there's a lot of progress to be made, but the images are at least plausibly bedroom-like.
preds = netG(create_noise(4))
pred_ims = md.trn_ds.denorm(preds)
fig, axes = plt.subplots(2, 2, figsize=(6, 6))
for i,ax in enumerate(axes.flat): ax.imshow(pred_ims[i])

Meanwhile, how is the network doing as an autoencoder?
i=1
fig = plt.figure()
((ax1,ax2)) = fig.subplots(1,2)
ax1.imshow(denorm(x)[i])
ax2.imshow(denorm(learn.model(x))[i])

Oops, not good. That's no surprise though since we've trained all the weights in the decoder layer except the translation layer, optimizing them for something the translation layer knows nothing about.
learn.save(f"AE_ph2")
learn.load(f"AE_ph2")
train(2, False)
Further training seems to be moving things in the right direction.
netD.eval(); netG.eval();
fake = netG(fixed_noise).data.cpu()
faked = np.clip(md.trn_ds.denorm(fake),0,1)
plt.figure(figsize=(9,9))
plt.imshow(gallery(faked, 8));

learn.save(f"AE_ph3")
learn.load(f"AE_ph3")
train(5, False)
netD.eval(); netG.eval();
fake = netG(fixed_noise).data.cpu()
faked = np.clip(md.trn_ds.denorm(fake),0,1)
plt.figure(figsize=(9,9))
plt.imshow(gallery(faked, 8));

preds = netG(create_noise(4))
pred_ims = md.trn_ds.denorm(preds)
fig, axes = plt.subplots(2, 2, figsize=(6, 6))
for i,ax in enumerate(axes.flat): ax.imshow(pred_ims[i])

learn.save(f"AE_ph4")
Etc.
In summary repurposing the GAN as an autoencoder was successful as a form of pretraining. Something I'll keep in mind for the future.